
Table of Contents
- Why Mental Models Matter
- Layer 1: State → Situational Logic
- Layer 2: Data → Shapes in Motion
- Layer 3: Graph → Structural Topology
- Layer 4: Composition → Assembly Strategy
- Layer 5: Effects → The Boundary
- Layer 6: Time → First-Class Citizen
- Layer 7: Cache → Memory Strategy
- Layer 8: Identity → The Reference
- Layer 9: Protocol → The Contract
- The Synthesis: How to Use This Stack
- Final Thoughts
The 9-Layer Mind Stack: A Unified Mental Model for Web Development
There are so many web frameworks to choose form nowadays: React, Vue, Solid, Svelte or even meta-frameworks like Next, and Nuxt. It can get confusing since they all seem different at a first glance. However, they all solve the same underlying concerns once you look past syntax and conventions.
Hence, the real question isn’t which framework to choose. It’s whether you understand the mental model underneath them. Without that understanding, architectural decisions can be reactive. You’d feel like those abstractions are magical. From this angle, those so-called framework experts are just “conjurers of cheap tricks.” One might call them “frameworkers.” What’s a frameworker? Someone who can only think in framework-specific patterns.
To avoid that trap, I’ve developed a single mental model that cuts across frameworks entirely. This article lays out a nine-layer stack I use to reason about web applications, from state and data flow to protocols and system boundaries.
Why Mental Models Matter
All web development frameworks can be reduced to a small number of foundational principles. Those principles become your architectural vocabulary. You define boundaries before writing code. When you think in these terms, frameworks no longer dictate your design. You’d see them as mere implementation details.
Let’s break down the stack.
Layer 1: State → Situational Logic
Core Principle: All meaningful behaviour in software is stateful, and explicit state modeling prevents implicit bugs.
Think of state as your application’s “current situation.” A login form isn’t just a form. It’s a machine that can be idle, loading, successful, or displaying an error. It can’t be in two of these states simultaneously.
Finite State Machines (FSMs) formalize this. Instead of scattering boolean flags (isLoading, hasError, isSuccess) across your code, you define explicit states and valid transitions between them.
For complex UIs, you’ll need Hierarchical State Machines. States within states, like folders within folders. An authenticated user might be in an “active” or “idle” sub-state.
When you’re building collaborative tools (think Google Docs), you need advanced reconciliation strategies:
-
Operational Transformation (OT): A central server transforms conflicting edits so everyone sees the same result
-
CRDTs (Conflict-free Replicated Data Types): Math-based data structures that guarantee convergence without a central authority
For financial systems or audit trails, Event Sourcing treats every change as an immutable event. Instead of storing “balance: $80,” you store “deposited $100, spent $20.”
The progression:

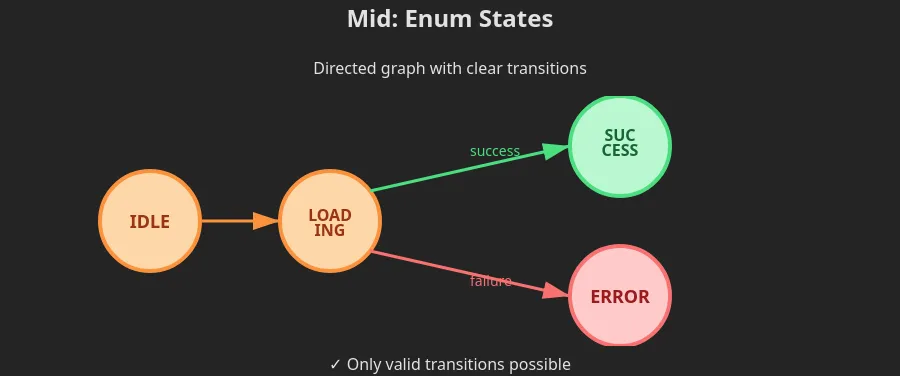
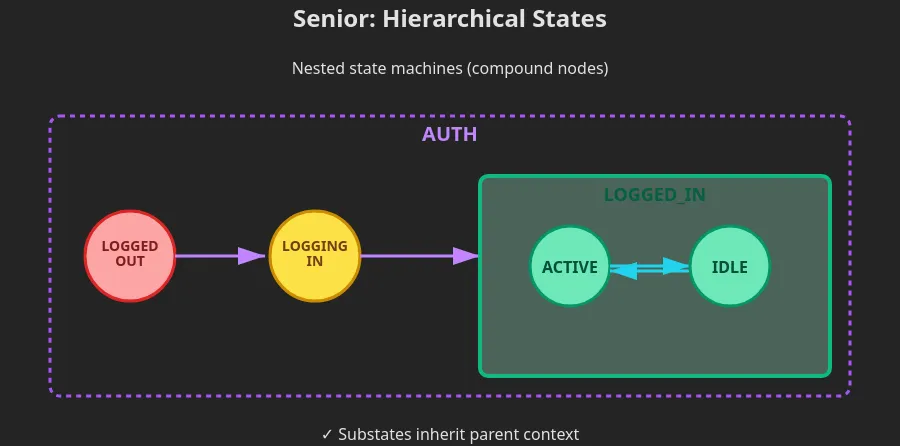
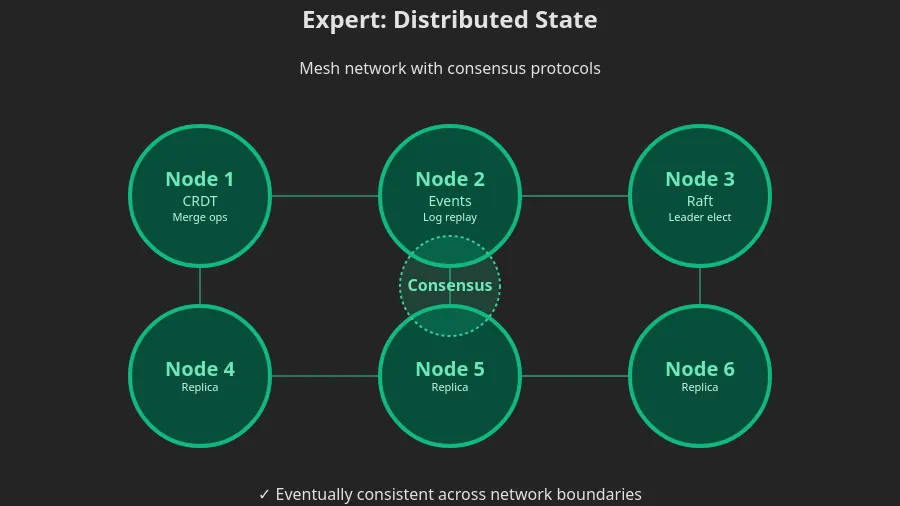
Bugs are often illegal state transitions. If you enumerate all possible states in advance, half your bugs disappear.
Layer 2: Data → Shapes in Motion
Core Principle: Data transforms across boundaries, and mismatched shapes cause system fractures.
As your data moves through your stack, it takes on many forms. A user object in your database looks different from the JSON your API returns, which in turn looks different from what your UI component needs.
Static type systems (TypeScript interfaces, JSON Schema) detect shape mismatches at development time. Runtime validation (Zod, Yup, Joi) catches them when real users send unexpected data.
Static types help you write code. Runtime validation protects your app from the outside world.
As your system evolves, you need migration strategies:
-
Versioned APIs: Keep old endpoints running while new clients use updated ones
-
Schema migrations: Careful scripts that transform database structures without causing any downtime
Mutability contracts define whether data can change:
-
Mutable: Fast but risky
-
Immutable: Safe but slower
-
Transient: Modifiable while being processed, frozen after
Transformation steps:
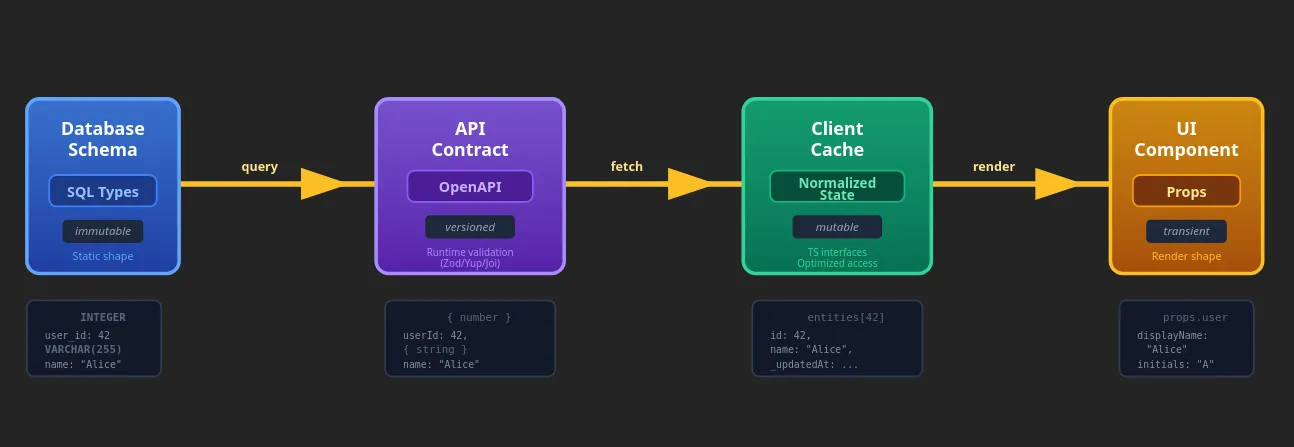
Every boundary (DB ↔ API ↔ UI) is a shape transformation. Type errors are just shape mismatches caught at different times.
Layer 3: Graph → Structural Topology
Core Principle: Systems seem hierarchical, but function as graphs; understanding connections prevents bottlenecks.
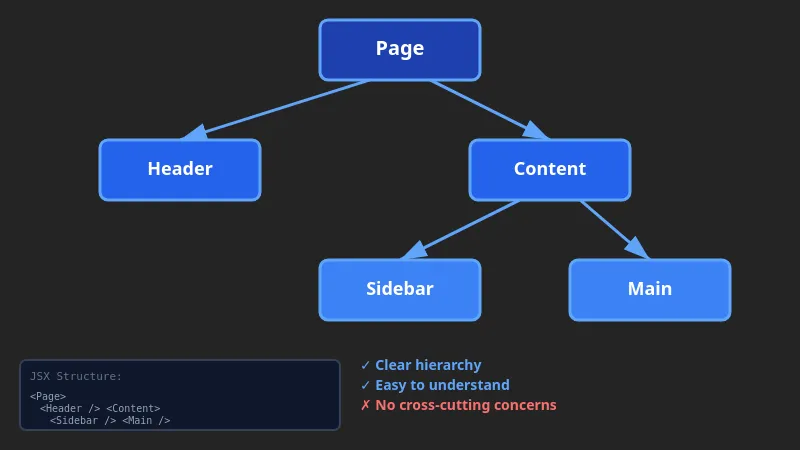
Your component tree looks neat and well-organized, but under the hood, it’s a web of dependencies. File A imports File B, which imports File C, which… imports File A. Circular dependency, and your build breaks.
Trees are for containment (DOM, component hierarchies, file systems)
Move the parent and everything inside moves with it.
Graphs are for dependencies (data flow, module imports, microservices)
Everything can connect to everything else.
Cycles are risk. Circular dependencies create “Mexican standoffs” where modules can’t load. Infinite loops freeze your app. In React, careless useEffect calls lead to infinite re-render cycles.
Layering is the solution: impose tree structure on graph problems. Force data to flow down, requests to flow up. The classic three-tier architecture (presentation → business logic → data access) is just layering in disguise.
Pattern recognition:
-
Tree thinking: UI hierarchies
-
Graph thinking: Data dependencies
-
Layer thinking: System architecture
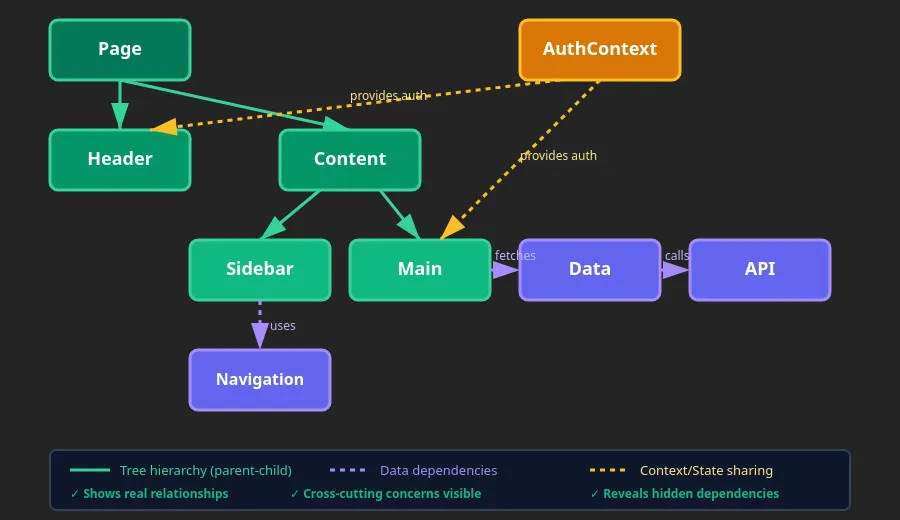
Important realization: Performance problems are often graph traversal issues. Testing difficulty scales with graph complexity.
Layer 4: Composition → Assembly Strategy
Core Principle: Systems scale through composition, but composition has diminishing returns.
Instead of one giant function that does everything, you write small functions and link them together.
Function composition is like an assembly line. The output of one function becomes the input for the next. Middleware chains are security checkpoints. Each function checks something before passing the request along.
Component composition is building UIs like Lego. Slots and children let you create containers that don’t care what goes inside. Higher-Order Components wrap components to add superpowers (authentication, loading states, error boundaries).
Service composition breaks monolithic backends into microservices.
Pipeline composition moves data through transformation stages (ETL processes, build systems).
The curve of composition:
-
Under-composed: Monolithic, difficult to test
-
Sweet spot: The highest possible value
-
Over-composed: Fragmented, impossible to debug
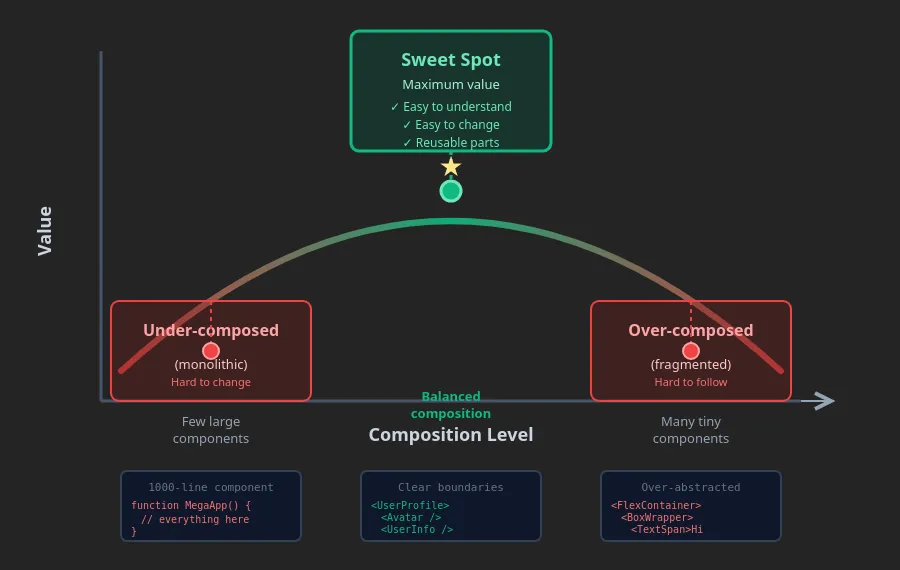
Important realization: Reusability comes from orthogonal composable units. However, excessive composition kills debuggability.
Layer 5: Effects → The Boundary
Core Principle: Side effects are system risks that must be controlled and observed.
Pure functions are predictable: same input, same output. Effects are everything else including network calls, disk writes, user input, randomness…
I/O operations communicate with the external environment.
Non-determinism means running the same code twice might give different results.
Resource management ensures you don’t leak memory or connections.
Observability (logging, metrics, tracing) is your black box recorder. When production breaks at 3 AM, logs are your only friend.
The hierarchy of effects:
-
Core logic (pure, testable)
-
Effect adapters (abstraction layer)
-
Effect implementations (fetch, localStorage, DOM)
-
Effect observability (logging, monitoring)
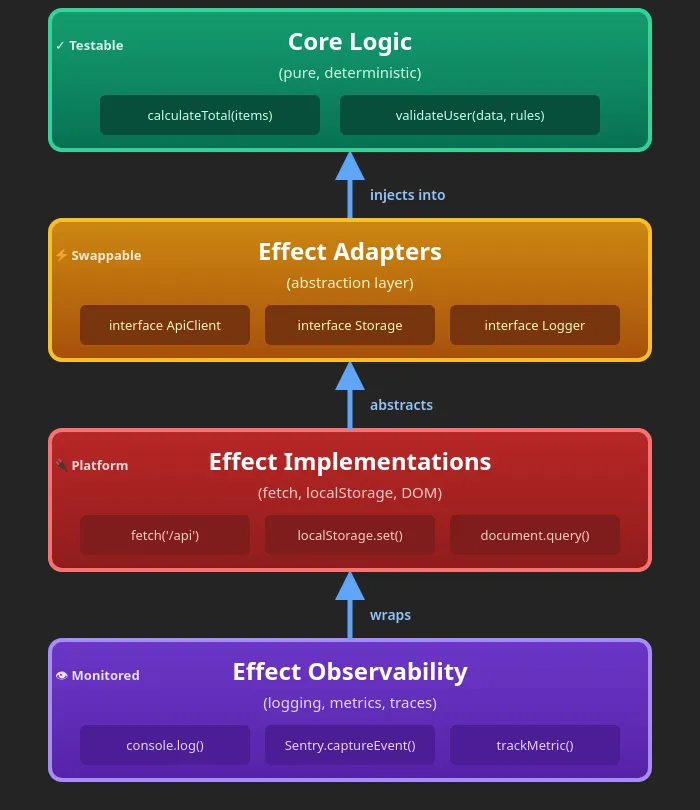
Important realization: Pure logic is testable. Logic that results in side-effects is risky. Production debugging requires effect tracing.
Layer 6: Time → First-Class Citizen
Core Insight: Distributed systems don’t have “now”, they have competing timelines that must be reconciled.
In a single-threaded app, time is simple. In distributed systems, every server has its own clock, and they’re never perfectly synced.
Ordering guarantees define when messages arrive:
-
Sequential: Guaranteed order, but slow
-
Eventual: Fast, but might be out of order temporarily
-
Causal: Respects cause-and-effect relationships
Consistency models determine how quickly users see updates:
-
Strong consistency: Slow but accurate
-
Eventual consistency: Fast but briefly stale
-
Optimistic consistency: Assume success, fix conflicts later
Time-bound operations prevent infinite waits:
-
Timeouts: Give up after N seconds
-
Retries: Try again if it fails
-
Debouncing: Wait until user stops typing
Distributed time uses vector clocks or logical timestamps because you can’t trust wall clocks across servers.
Important realization: Race conditions are a result of time modeling failures. Data integrity requires understanding time in distributed systems.
Layer 7: Cache → Memory Strategy
Core Principle: Performance is systemic, not incidental. Caching strategy determines scalability.
Derived state is information you calculate rather than store. Don’t store both birth year and age. Store birth year and derive the age. Redundancy causes bugs.
Storage layers trade speed for capacity:
-
Client cache: 1ms latency, free
-
Edge cache: 10ms, inexpensive
-
Server cache: 50ms, moderate cost
-
Database: 100ms+, expensive
Invalidation strategies determine when cache expires:
-
Time-based: Stale after N minutes
-
Event-based: Invalidate when source changes
-
Explicit: Manual cache busting
Consistency trade-offs balance speed and accuracy:
-
Stale-while-revalidate: Show old data, fetch new in background
-
Write-through: Update cache and database simultaneously
The cache matrix: Every layer has different freshness, latency, cost, and invalidation rules.
Important realization: When performance becomes an issue, caching is unavoidable. Cache boundaries double as security boundaries.
Layer 8: Identity → The Reference
Core Principle: How you point to things determines system consistency and complexity.
Identity types distinguish objects:
-
Global UUIDs: Unique across all systems
-
Local references: Unique within one context
-
Composite keys: Multiple fields combined
Equality semantics define “sameness”:
-
Reference equality: Same box?
-
Value equality: Same contents?
-
Deep equality: Recursively same contents?
Normalization strategies organize data to avoid duplication:
-
By-ID: Store once, reference by key
-
Nested: Embed related data
-
Graph: Store relationships explicitly
Reference integrity prevents orphaned data. Foreign keys ensure books don’t point to deleted authors. Cascading deletes clean up related records automatically.
The identity spectrum: Embedded data (tight coupling) → References → Event sourcing (loose coupling)
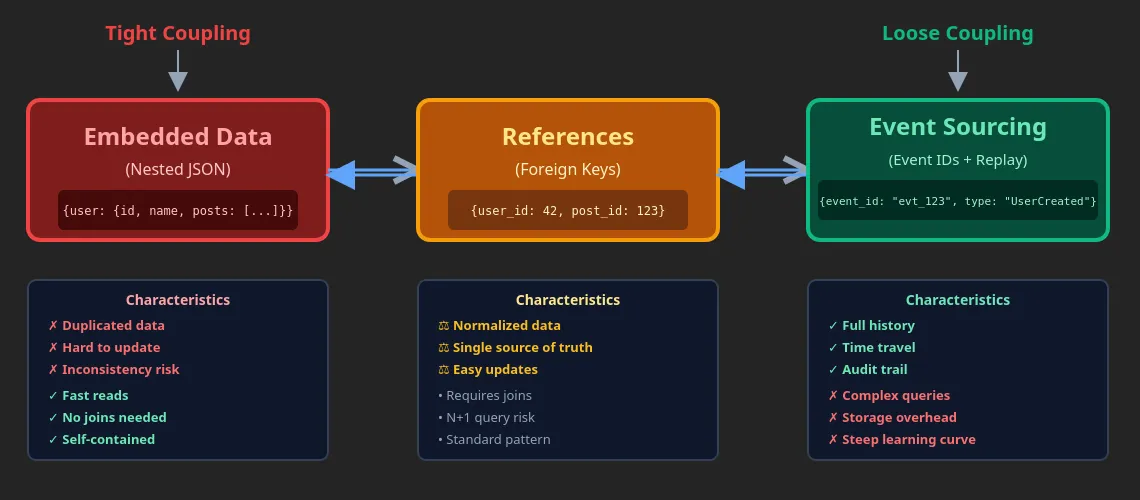
Important realization: Data synchronization depends on identity resolution. System complexity results from identity mismatches.
Layer 9: Protocol → The Contract
Core principle: Systems communicate through protocols, and protocol evolution is system evolution.
Communication patterns define how systems talk:
-
Request/response: Ask, wait, receive
-
Pub/sub: Broadcast to many listeners
-
Streaming: Continuous data flow
Delivery guarantees promise how many times messages arrive:
-
At-most-once: Might be lost (fast, unreliable)
-
At-least-once: Might duplicate (reliable, needs deduplication)
-
Exactly-once: Perfect delivery (slow, complex)
Evolution strategies let systems change without breaking:
-
Versioning: Run old and new APIs simultaneously
-
Feature flags: Toggle features on/off
-
Backward compatibility: New code works with old clients
Transport choices move data between systems:
-
HTTP/2: Standard web requests
-
WebSockets: Real-time bidirectional
-
Server-Sent Events: Server pushes updates
-
QUIC: Modern, optimized for mobile
Protocol selection:
-
Simple CRUD: REST or GraphQL
-
Real-time updates: WebSockets or SSE
-
Mobile networks: HTTP/3 (QUIC)
-
Internal services: gRPC
Important realization: Protocol semantics dictate client implementation. Long-term maintenance requires versioning.
The Synthesis: How to Use This Stack
Think of these layers as lenses you apply to any problem.
For a new feature:
-
Model the state machine (Layer 1)
-
Define data shapes (Layer 2)
-
Map component connections (Layer 3)
-
Compose from existing parts (Layer 4)
-
Isolate side effects (Layer 5)
-
Handle async flows (Layer 6)
-
Add caching where needed (Layer 7)
-
Establish identity semantics (Layer 8)
-
Choose communication protocol (Layer 9)
For debugging:
-
Check protocol errors (Layer 9)
-
Verify identity resolution (Layer 8)
-
Examine cache consistency (Layer 7)
-
Trace timing issues (Layer 6)
-
Isolate effect failures (Layer 5)
-
Test component isolation (Layer 4)
-
Verify data flow (Layer 3)
-
Validate data shapes (Layer 2)
-
Check state transitions (Layer 1)
Final Thoughts
This isn’t 9 separate concepts. It’s a single mental model viewed from 9 angles. Each layer explains a different class of failure modes, optimization opportunities, and architectural trade-offs.
The art of web development isn’t about mastering all layers at once. It’s about recognizing which layer a problem belongs to, and understading how decisions made there propagate through the system.
Frameworks will come and go. Tooling will improve. These fundamentals remain.